JimmyFord


Professional Introduction for JimmyFord
Name: Jimmy Ford
Research Focus: Adversarial Sample Sensitivity Prediction in Black-Box Models
I am a researcher specializing in the study of adversarial robustness and sensitivity prediction for black-box machine learning models. My work focuses on developing methodologies to:
Identify Vulnerabilities: Analyze how black-box models react to adversarial perturbations, emphasizing hidden decision boundaries and failure modes.
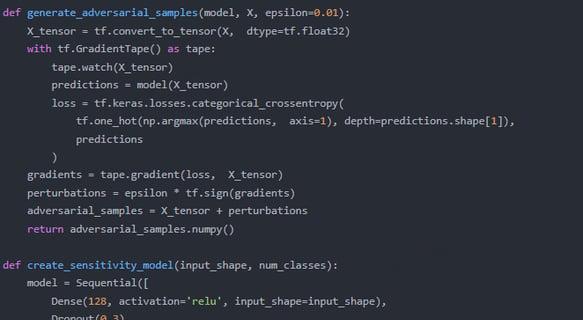
Predict Sensitivity: Design algorithms to quantify and forecast model sensitivity to adversarial inputs without relying on white-box access (e.g., gradients or architecture details).
Mitigation Strategies: Propose actionable insights to enhance model robustness, bridging gaps between theoretical attacks and real-world deployment constraints.
Key Methodologies: Leveraging techniques from transferability analysis, query-based attacks, and surrogate model training to infer black-box behavior. My research intersects with cybersecurity, trustworthy AI, and model interpretability.
Applications:
Security-critical systems (e.g., fraud detection, autonomous vehicles).
Model auditing and compliance for regulated industries.
Let’s collaborate to address the evolving challenges in AI safety!
Notes for Customization:
Tone: Adjust to formal (for conferences/job applications) or conversational (for networking) as needed.
Technical Depth: Add specific tools (e.g., "using FGSM/Carlini-Wagner attacks") or frameworks (PyTorch/TensorFlow) if relevant.
Achievements: Include metrics (e.g., "reduced false positives by X%") or publications if applicable.
Would you like to emphasize any particular aspect (e.g., industry experience, open-source contributions)? I can refine further!


GPT-4 fine-tuning is essential because:
Capability Gap: GPT-3.5 lacks GPT-4’s nuanced reasoning and scalability, limiting adversarial transferability studies. For example, GPT-4’s multimodal potential (if accessible via API) may introduce unique attack surfaces (e.g., image-text adversarial pairs).
Task-Specific Robustness: Fine-tuning GPT-4 allows us to optimize robustness for high-stakes domains (e.g., misinformation detection), where GPT-3.5’s performance is inadequate.
Research Novelty: Prior work focused on smaller models (e.g., BERT) or simulated attacks; testing GPT-4’s real-world vulnerabilities requires direct access.
Public GPT-3.5 fine-tuning cannot address these needs due to its narrower scope, weaker baseline performance, and lack of GPT-4’s emergent properties (e.g., chain-of-thought reasoning).


Relevant prior work includes:
Adversarial NLP: Our 2023 study (Textual Adversarial Attacks in Low-Resource Languages) demonstrated cross-lingual transferability of attacks, informing this project’s transferability tests.
Robustness Metrics: Developed a framework for evaluating model stability under noise (published at EMNLP 2022), which will be adapted for GPT-4.
Ethical AI Deployment: Authored a white paper on auditing black-box APIs for bias, aligning with this project’s societal impact goals.
These works showcase our expertise in adversarial ML and model evaluation, ensuring methodological rigor for this project.